Aaron Feng
I am a recent mechanical engineering graduate from the University of Michigan Ann Arbor. Growing up, I witnessed the development and technical breakthroughs of reusable rockets, private spaceflight, robotic interplanetary exploration, sustainable transportation, and more. This led me to develop a strong passion for engineering, a desire to push the boundaries of what is possible, and to create a lasting impact on society.
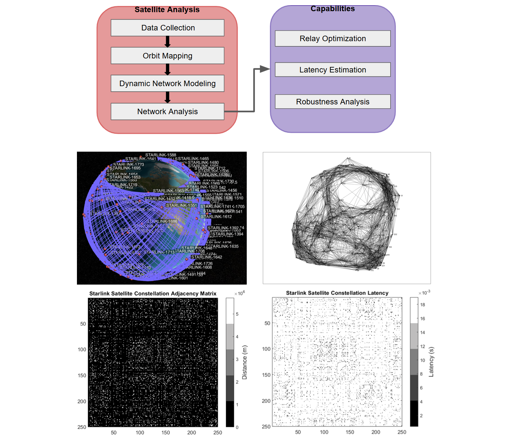
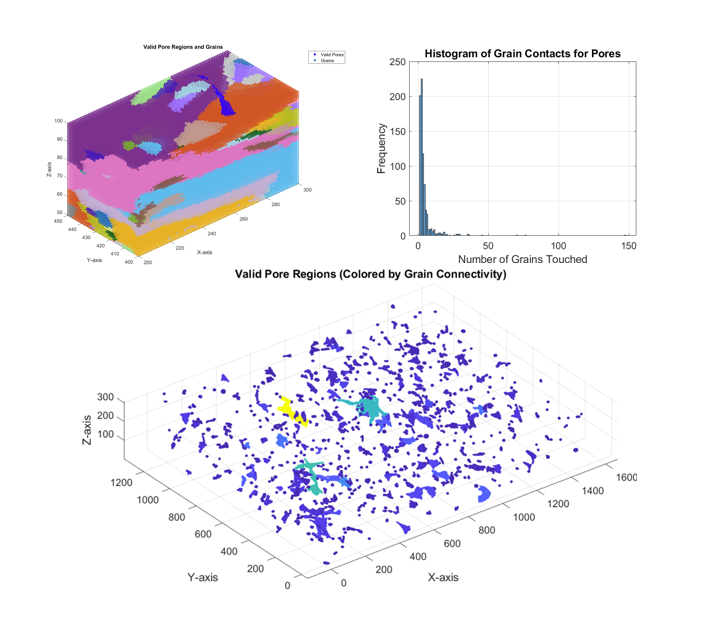
Throughout my extensive work experiences in the aerospace and automotive industries, I have gained skills and perspectives in many aspects of engineering, including design, simulation/analysis, software, and manufacturing. This portfolio details those, as well as some of the other projects that I have worked on.